|
|
|
|
Safety_Critical_Machine_Learning |
|


|
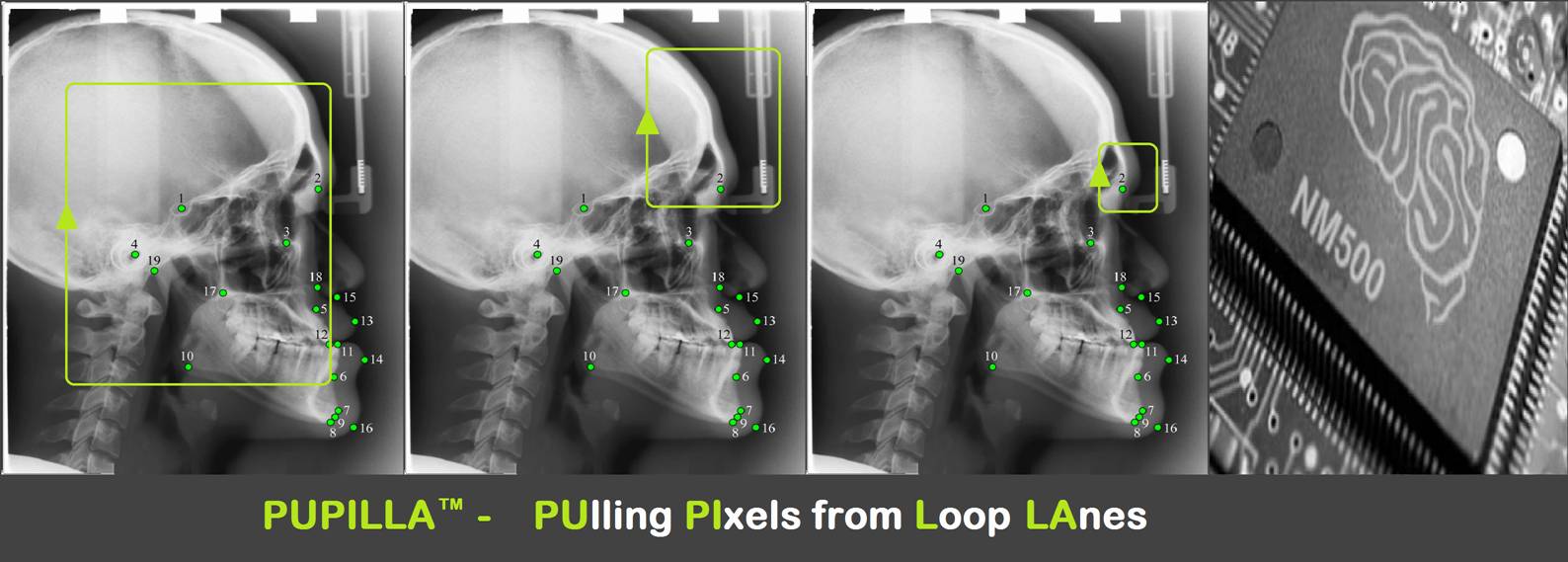
The simplest version of the PUPILLA™
algorithm has been successfully tested on orthodontic landmark detection.
This test demonstrates that a spatially aware, moving focus computer vision
model, more similar to human vision, has high potential and is more efficient
than algorithms such as CNN, allowing its implementation on low-power
devices. |
|
|
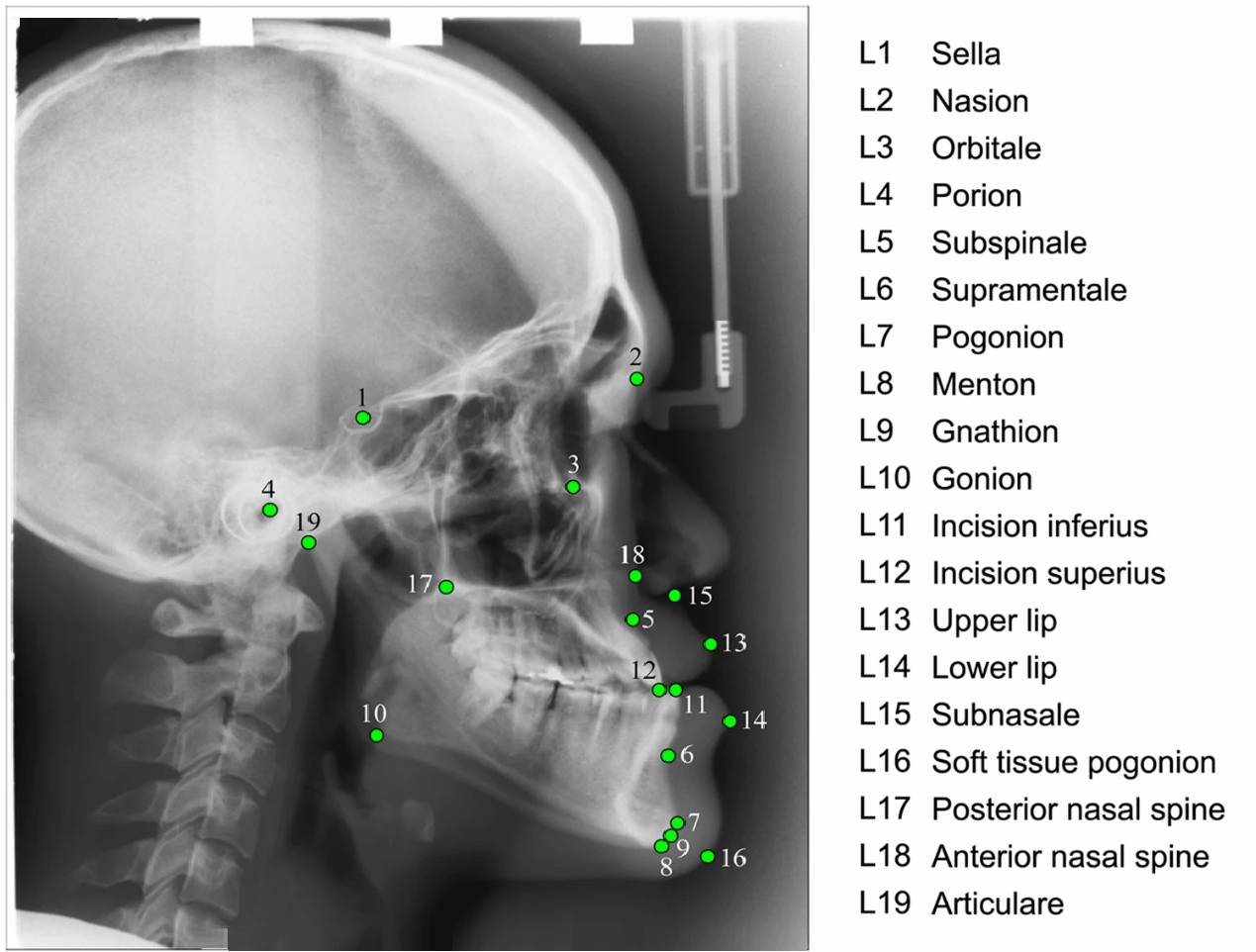
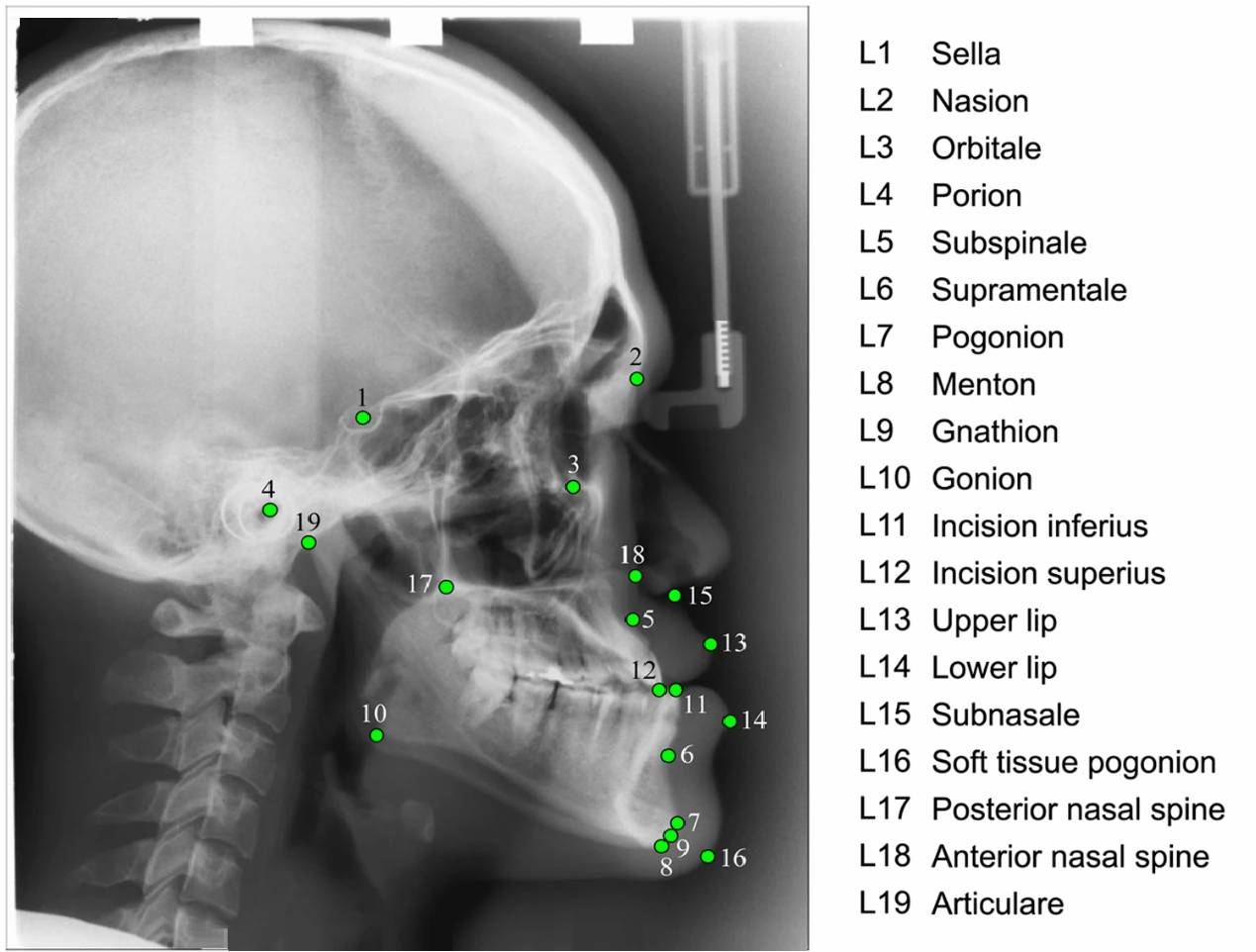
Orthodontic landmark detection involves
identifying specific points on radiographic images of the skull
(cephalograms) to assess craniofacial structures and guide orthodontic
treatment. These landmarks are used to measure angles and distances,
helping to diagnose dental and skeletal problems, plan treatment, and
evaluate results. Traditionally, this process was done manually, but
automated landmark detection using artificial intelligence (AI) is
increasingly being used to improve efficiency, accuracy, and consistency. In summary,
orthodontic landmark detection is a crucial aspect of orthodontic diagnosis
and treatment planning. While manual methods are still used, the rise of
AI-based systems promises to enhance the efficiency, accuracy, and
reliability of this process. PUPILLA™ is an
algorithm that progressively moves the focus towards the target area,
successfully implemented with Neuromem® technology. While
a CNN vision has a completely uniform level of detail across the entire field
of view, PUPILLA™ implements the functioning of human vision in which the
perception of detail loses precision away from the focus. PUPILLA™ implements
a focusing hierarchy similar to that used by the human mind and eye in the
processing of an image. This image processing principle that shifts and
narrows the focus through a hierarchical cognitive process requires less
computational power and lower energy consumption. The implementation of PUPILLA™ on a Neuromem®
chip has allowed obtaining cephalometric landmark determination with the same
precision as deep learning applications, with less than 1000 images from the
same X-ray machine. The great advantage of the Neuromem® solution
is related to the possibility of refining the point determination mechanism
with new learnings that can be performed on the very low-power edge without
affecting previous learning. PUPILLA™ is a simple and intuitive algorithm,
whose effectiveness has been demonstrated in the task of identifying
cephalometric landmarks but which can be used in many other sectors. In
particular, the algorithm can be used in determining the position of
sub-elements in all images in which there is a positional correlation between
them. Below we explain how the PUPILLA™ algorithm
works in an example of determining the position of the L2 point (Nasion),
also referring to the functions of the Neuromem® API. The PUPILLA™ algorithm is actually more
sophisticated than what is presented below. In fact, however, the solution
presented below is exactly the one that allowed us to obtain the position of
the orthodontic landmarks with satisfactory precision. |
|

|
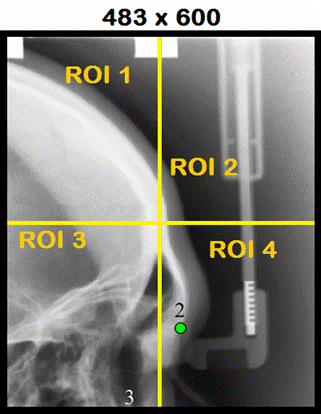
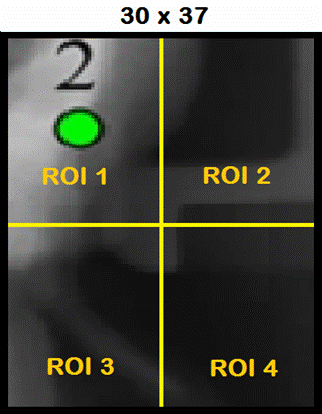
PUPILLA algorithm
example: determination of landmark L2 (Nasion) |
|
|
9 Catagories: Cat1=UP, Cat2=DOWN, Cat3=RIGHT, Cat4=LEFT, Cat5=UP-RIGHT, Cat6=UP-LEFT, Cat7=DOWN-RIGHT, Cat8=DOWN-LEFT, Cat9=INSIDE |
|
|
Learning Phase |
|
|
|
Neuromem® Context 1
ROI1, ROI2, ROI3, ROI4: Sub-sampling 16x16 Learn ROI1 = Cat3 Learn ROI2 = Cat9 Learn ROI3 = Cat5 Learn ROI4 = Cat1 SetContext(int
context, int minif, int maxif); void
SetROI(int Width, int Height); int
LearnROI(int Left, int Top int Category); |
|
|
ROI2: Sub-sampling x 2 Neuromem® Context 2
ROI1, ROI2, ROI3, ROI4: Sub-sampling 16x16 Learn ROI1 = Cat7 Learn ROI2 = Cat2 Learn ROI3 = Cat3 Learn ROI4 = Cat9 SetContext(int
context, int minif, int maxif); void
SetROI(int Width, int Height); int
LearnROI(int Left, int Top int Category); |
|
|
ROI4: Sub-sampling x 2 Neuromem® Context 3
ROI1, ROI2, ROI3, ROI4: Sub-sampling 16x16 Learn ROI1 = Cat2 Learn ROI2 = Cat8 Learn ROI3 = Cat9 Learn ROI4 = Cat4 SetContext(int
context, int minif, int maxif); void
SetROI(int Width, int Height); int LearnROI(int
Left, int Top int Category); |
|
|
ROI3: Sub-sampling x 2 Neuromem® Context 4
ROI1, ROI2, ROI3, ROI4: Sub-sampling 16x16 Learn ROI1 = Cat9 Learn ROI2 = Cat4 Learn ROI3 = Cat1 Learn ROI4 = Cat6 SetContext(int
context, int minif, int maxif); void
SetROI(int Width, int Height); int
LearnROI(int Left, int Top int Category); |



|
Recognition Phase |
|
|
|
Neuromem® Context 1
ROI1, ROI2, ROI3, ROI4: Sub-sampling 16x16 Recognize ROI1 => Cat3 Recognize ROI2 => Cat9 Recognize ROI3 => Cat5 Recognize ROI4 => Cat1 SetContext(int
context, int minif, int maxif); void
SetROI(int Width, int Height); int
RecognizeROI(int Left, int Top int K, int *distances, int
*categories, int *nids); (ROI1==Cat3) &
(ROI2==Cat9) & (ROI3==Cat5) & (ROI4==Cat1) => ROI2 |
|
|
ROI2: Sub-sampling x 2 Neuromem® Context 2
ROI1, ROI2, ROI3, ROI4: Sub-sampling 16x16 Recognize ROI1 => Cat7 Recognize ROI2 => Cat2 Recognize ROI3 => Cat3 Recognize ROI4 => Cat9 SetContext(int
context, int minif, int maxif); void
SetROI(int Width, int Height); int
RecognizeROI(int Left, int Top int K, int *distances, int
*categories, int *nids); (ROI1==Cat7) & (ROI2 ==
Cat2) & (ROI3 == Cat3) & (ROI4 == Cat9) => ROI4 |
|
|
ROI4: Sub-sampling x 2 Neuromem® Context 3
ROI1, ROI2, ROI3, ROI4: Sub-sampling 16x16 Recognize ROI1 => Cat2 Recognize ROI2 => Cat8 Recognize ROI3 => Cat9 Recognize ROI4 => Cat4 SetContext(int
context, int minif, int maxif); void SetROI(int
Width, int Height); int
RecognizeROI(int Left, int Top int K, int *distances, int
*categories, int *nids); (ROI1==Cat2) &
(ROI2==Cat8) & (ROI==Cat9) & (ROI4==Cat4) => ROI3 |
|
|
ROI3: Sub-sampling x 2 Neuromem® Context 4
ROI1, ROI2, ROI3, ROI4: Sub-sampling 16x16 Recognize ROI1 = Cat9 Recognize ROI2 = Cat4 Recognize ROI3 = Cat1 Recognize ROI4 = Cat6 SetContext(int
context, int minif, int maxif); void
SetROI(int Width, int Height); int
RecognizeROI(int Left, int Top int K, int *distances, int
*categories, int *nids); (ROI1==Cat9) &
(ROI2==Cat4) & (ROI==Cat1) & (ROI4==Cat6) => ROI1 |
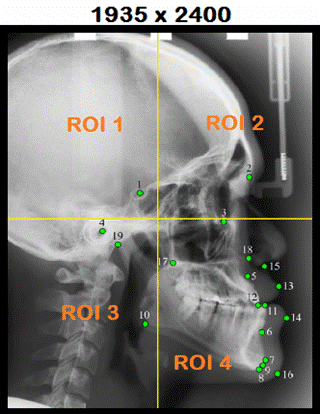
L2 (Nasion) RESEARCH FOCUS PATH
|
|
|
General Synaptics Aerospace_and_Defence_Machine_Learning_Company VAT NUMBER:_IT02670700992 REA NUMBER: GE-503104 Email:_luca.marchese@synaptics.org |
|
|
|
Copyright© 2026 General Synaptics |